
Architecture#
Basic need is first checking URLs in markdown files for Jupyter Book or Sphinx documentation. However a URL check is a bit universal, so some room for future needs should be possible.
Core architecture principles used for design and implementation:
Modular architecture. So adding functionality or making improvements should be simple.
Secure-by-design
Automatic testing of core functions. This to prevent issues when adjusting things later.
Fast: Large amounts of URLs should be validated asynchronous.
Simple: So simple to use and simple to maintain. And avoid scope creep! Scope creep makes maintenance painful in the long run.
Note:
Testing Python functions that use
asynciowithpytestis not trivial. But a good pytest plugin exist to manage testing functions that useasyncio.
Overview#
High level software architecture overview of modules:
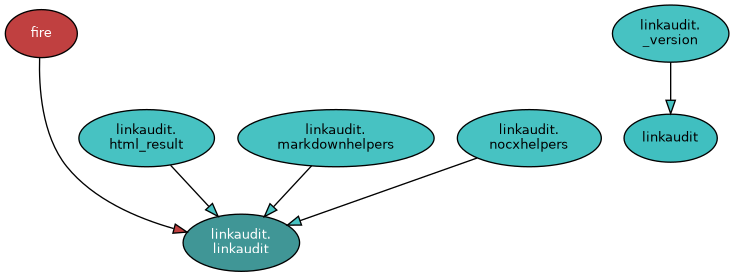
URLs are checked on:
DNS presence and
HTTP status (if reachable)
Design decisions#
During creation a number of challenges appeared. Following design principles are used for steering implementation:
Per markdown file all URLs are checked in parallel. You could first collect all links from all files and test all links in parallel, but for now there is no extra value to create this YGNI.
URL detection in Sphinx / Jupyterbook documenttion , so
markdown,MySTandrstfiles is not trivial. This has resulted in some complex regex logic to determine if a URL must be checked. Testing correct detection of URLs resulted to be a MUST.Google Fire module is used to simplify and speed up the creation of a CLI Python. application. There are many other options, but
Fireworks, is battle tested and is provides features needed.
Current know issues and limitations#
URLs that require a login can give
HTTP Error: 403 Forbidden. E.g. private Github repositories.Timeouts
Unexpected Error: The read operation timed outSome URLs are valid and can be reached. But are slow. This can result in a timeout.URLs of sites that do in-depth finger printing. Some sites can not easily be accessed using a CLI program. Besides a standard
user-agentcheck large sites use very nasty finger printing techniques to avoid all kind ofcrawlersfor accessing URLs.
Build the documentation#
Build the API documentation for all modules:
First build the API documentation again:
sphinx-apidoc -M -o docs [../src/linkaudit]
Build the Jupyterbook again:
From the /docs directory do:
jb build .
*Required is Jupyterbook to build the documentation or Sphinx.