
ML Reference Architecture#
When you are going to apply machine learning for your business for real you should develop a solid architecture. A good architecture covers all crucial concerns like business concerns, data concerns, security and privacy concerns. And of course a good architecture should address technical concerns in order to minimize the risk of instant project failure.
Unfortunately it is still not a common practice for many companies to share architectures as open access documents. So most architectures you will find are more solution architectures published by commercial vendors.
Architecture is a minefield. And creating a good architecture for new innovative machine learning systems and applications is an unpaved road. Architecture is not by definition high level and sometimes relevant details are of the utmost importance. But getting details of the inner working on the implementation level of machine learning algorithms can be very hard. So a reference architecture on machine learning should help you in several ways.
Unfortunately there is no de-facto single machine learning reference architecture. Architecture organizations and standardization organizations are never the front runners with new technology. So there are not yet many mature machine learning reference architectures that you can use. You can find vendor specific architecture blueprints, but these architecture mostly lack specific architecture areas as business processes needed and data architecture needed. Also the specific vendor architecture blueprints tend to steer you into a vendor specific solution. What is of course not always the most flexible and best fit for your business use case in the long run.
In this section we will describe an open reference architecture for
machine learning. Of course this reference architecture is an open
architecture, so open for improvements and discussions. So all input is
welcome to make it better! See section Help <Help>{.interpreted-text
role=”ref”}.
The scope and aim of this open reference architecture for machine learning is to enable you to create better and faster solution architectures and designs for your new machine learning driven systems and applications.
You should also be aware of the important difference between:
Architecture building Blocks and
Solution building blocks
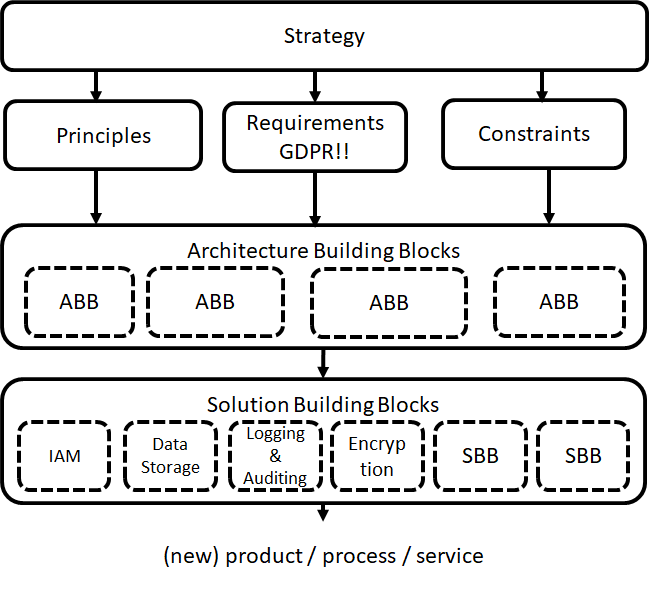
This reference architecture for machine learning describes architecture building blocks. So you could use this reference architecture and ask vendors for input on for delivering the needed solution building blocks. However in another section of this book we have collected numerous great FOSS solution building blocks so you can create an open architecture and implement it with FOSS solution building blocks only.
Before describing the various machine learning architecture building blocks we briefly describe the machine learning process. This because in order to setup a solid reference architecture high level process steps are crucial to describe the most needed architecture needs.
Applying machine learning for any practical use case requires beside a good knowledge of machine learning principles and technology also a strong and deep knowledge of business and IT architecture and design aspects.
The machine learning process#
Setting up an architecture for machine learning systems and applications requires a good insight in the various processes that play a crucial role. The basic process of machine learning is feed training data to a learning algorithm. The learning algorithm then generates a new set of rules, based on inferences from the data. So to develop a good architecture you should have a solid insight in:
The business process in which your machine learning system or application is used.
The way humans interact or act (or not) with the machine learning system.
The development and maintenance process needed for the machine learning system.
Crucial quality aspects, e.g. security, privacy and safety aspects.
In its core a machine learning process exist of a number of typical steps. These steps are:
Determine the problem you want to solve using machine learning technology
Search and collect training data for your machine learning development process.
Select a machine learning model
Prepare the collected data to train the machine learning model
Test your machine learning system using test data
Validate and improve the machine learning model. Most of the time you need is to search for more training data within this iterative loop.
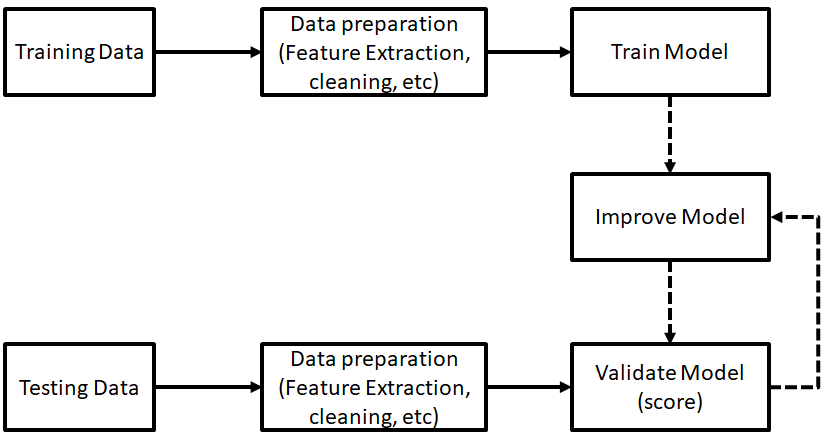
You need to improve your machine learning model after the first test. Improving can be done using more training data or by making model adjustments.
Architecture Building Blocks for ML#
This reference architecture for machine learning gives guidance for developing solution architectures where machine learning systems play a major role. Discussions on what a good architecture is, can be a senseless use of time. But input on this reference architecture is always welcome. This to make it more generally useful for different domains and different industries. Note however that the architecture as described in this section is technology agnostics. So it is aimed at getting the architecture building blocks needed to develop a solution architecture for machine learning complete.
Every architecture should be based on a strategy. For a machine learning system this means an clear answer on the question: What problem must be solved using machine learning technology? Besides a strategy principles and requirements are needed.
The way to develop a machine learning architecture is outlined in the figure below.
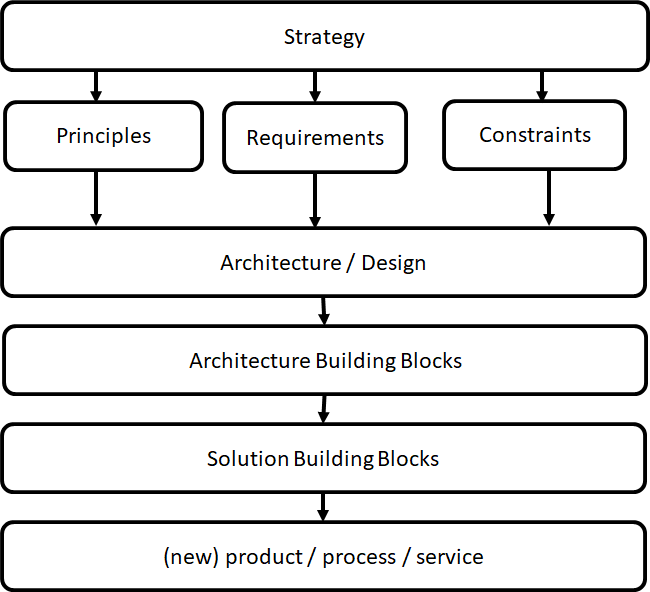
In essence developing an architecture for machine learning is equal as for every other system. But some aspects require special attention. These aspects are outlined in this reference architecture.
Principles for Machine learning#
Every good architecture is based on principles, requirements and constraints.This machine learning reference architecture is designed to simplify the process of creating machine learning solutions.
Principles are statements of direction that govern selections and implementations. That is, principles provide a foundation for decision making. A good principle hurts. Always good and common sense principles are nice for vision documents and policy makers. But when it comes to creating tangible solutions you must have principles that steer your development.
Principles are common used within business architecture and design and successful IT projects. A simple definition of a what a principle is:
A principle is a qualitative statement of intent that should be met by the architecture.
Every solution architecture that for business use of a machine learning application should hold a minimum set of core business principles.
Machine learning architecture principles are used to translate selected alternatives into basic ideas, standards, and guidelines for simplifying and organizing the construction, operation, and evolution of systems. In essence every good project is driven by principles. But since quality and cost aspects for machine learning driven application can have a large impact, a good machine learning solution is created based on principles.
Key principles that are used for this Free and Open Machine learning reference architecture are:
The most important machine learning aspects must be addressed.
The quality aspects: Security, privacy and safety require specific attention.
The reference architecture should address all architecture building blocks from development till hosting and maintenance.
Translation from architecture building blocks towards FOSS machine learning solution building blocks should be easily possible.
The machine learning reference architecture is technology agnostics. The focus is on the outlining the conceptual architecture building blocks that make a machine learning architecture.
For your use case you must make a more explicit variant of one of the above general principles.
By writing down business principles is will be easier to steer discussions regarding quality aspects of the solution you are developing. Creating principles also makes is easier for third parties to inspect designs and solutions and perform risks analysis on the design process and the product developed.
Example Business principles for Machine Learning applications#
In this section some general principles for machine learning applications. For your specific machine learning application use the principles that apply and make them SMART. So include implications and consequences per principle.
Collaborate#
Statement: Collaborate Rationale: Successful creation of ML applications require the collaboration of people with different expertises. You need e.g. business experts, infrastructure engineers, data engineers and innovation experts. Implications: Organisational and culture must allow open collaboration.
Unfair bias#
Statement: Avoid creating or reinforcing unfair bias Rationale: Machine learning algorithms and datasets can reflect, reinforce, or reduce unfair biases. Recognize fair from unfair biases is not simple, and differs across cultures and societies. However always make sure to avoid unjust impacts on sensitive characteristics such as race, ethnicity, gender, nationality, income, sexual orientation, ability, and political or religious belief. Implications: Be transparent about your data and training datasets. Make models reproducible and auditable.
Built and test for safety#
Statement: Built and test for safety. Rationale: Use safety and security practices to avoid unintended results that create risks of harm. Design your machine learning driven systems to be appropriately cautious Implications: Perform risk assessments and safety tests.
Privacy by design#
Statement: Incorporate privacy by design principles. Rationale: Privacy by principles is more than being compliant with legal constraints as e.g. EU GDPR. It means that privacy safeguards,transparency and control over the use of data should be taken into account from the start. This is a hard and complex challenge.
Constraints#
Important constraints for a machine learning reference architecture are the aspects:
Business aspects (e.g capabilities, processes, legal aspects, risk management)
Information aspects (data gathering and processing, data processes needed)
Machine learning applications and frameworks needed (e.g. type of algorithm, easy of use)
Hosting (e.g. compute, storage, network requirements but also container solutions)
Security, privacy and safety aspects
Maintenance (e.g. logging, version control, deployment, scheduling)
Scalability, flexibility and performance
ML Reference Architecture#
A full stack approach is needed to apply machine learning. A full stack approach means that in order to apply machine learning successfully you must be able to master or at least have a good overview of the complete technical stack. This means for machine learning vertical and horizontal. With vertical we mean from hardware towards machine learning enabled applications. With horizontal we mean that the complete tool chain for all process steps must be taken into account.
The machine learning reference model represents architecture building blocks that can be present in a machine learning solution. Information architecture (IT) and especially machine learning is a complex area so the goal of the metamodel below is to represent a simplified but usable overview of aspects regarding machine learning. Using this model gives you a head start when developing your specific machine learning solution.
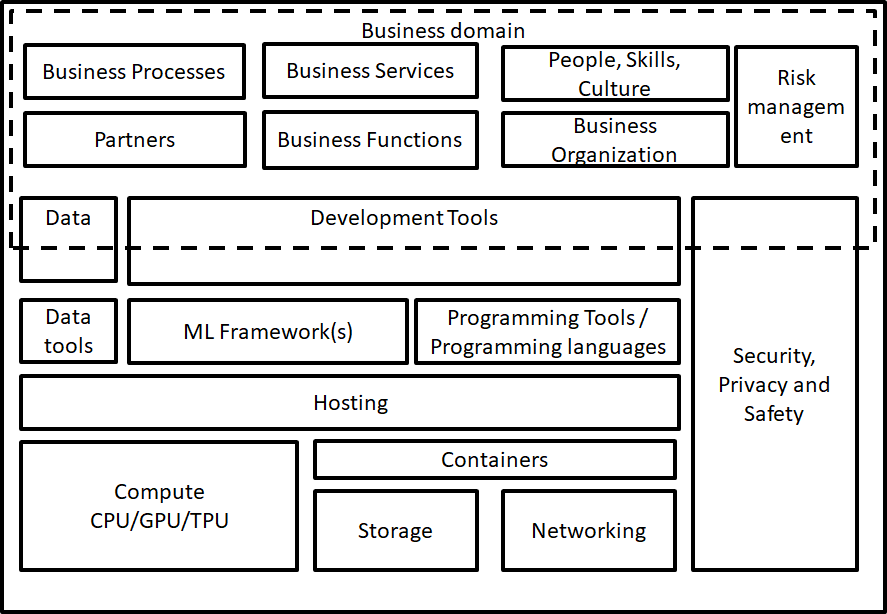
Conceptual overview of machine learning reference architecture.
Since this simplified machine learning reference architecture is far from complete it is recommended to consider e.g. the following questions when you start creating your solution architecture where machine learning is part of:
Do you just want to experiment and play with some machine learning models?
Do you want to try different machine learning frameworks and libraries to discover what works best for your use case? Machine learning systems never work directly. You need to iterate, rework and start all over again. Its innovation!
Is performance crucial for your application?
Are human lives direct or indirect dependent of your machine learning system?
In the following sections more in depth description of the various machine learning architecture building blocks are given.
Business Processes#
To apply machine learning with success it is crucial that the core business processes of your organization that are affected with this new technology are determined. In most cases secondary business processes benefit more from machine learning than primary processes. Think of marketing, sales and quality aspects that make your primary business processes better.
Business Services#
Business services are services that your company provides to customers, both internally and externally. When applying machine learning for business use you should create a map to outline what services are impacted, changed or disappear when using machine learning technology. Are customers directly impacted or will your customer experience indirect benefits?
Business Functions#
A business function delivers business capabilities that are aligned to your organization, but not necessarily directly governed by your organization. For machine learning it is crucial that the information that a business function needs is known. Also the quality aspects of this information should be taken into account. To apply machine learning it is crucial to know how information is exactly processes and used in the various business functions.
People, Skills and Culture#
Machine learning needs a culture where experimentation is allowed. When you start with machine learning you and your organization need to build up knowledge and experience. Failure is going to happen and must be allowed. Fail hard and fail fast. Take risks. However your organization culture should be open to such a risk based approach. IT projects in general fail often, so doing an innovative IT project using machine learning is a risk that must be able to cope with.
To make a shift to a new innovative experimental culture make sure you have different types of people directly and indirectly involved in the machine learning project. Also make use of good temporary independent consultants. So consultants that have also a mind set of taking risks and have an innovative mindset. Using consultants for machine learning of companies who sell machine learning solutions as cloud offering do have the risk that needed flexibility in an early stage is lost. Also to be free on various choices make sure you are not forced into a closed machine learning SaaS solution too soon. Since skilled people on machine learning with the exact knowledge and experience are not available you should use creative developers. Developers (not programmers) who are keen on experimenting using various open source software packages to solve new problems.
Business organization#
Machine learning experiments need an organization that stimulate creativity. In general hierarchical organizations are not the perfect placed where experiments and new innovative business concepts can grow.
Applying machine learning in an organization requires an organization that is data and IT driven. A perfect blueprint for a 100% good organization structure does not exist, but flexibility, learning are definitely needed. Depending on the impact of the machine learning project you are running you should make sure that the complete organization is informed and involved whenever needed.
Partners#
Since your business is properly not Amazon, Microsoft or Google you need partners. Partners should work with you together to solve your business problems. If you select partners pure doing a functional aspect, like hosting, data cleaning ,programming or support and maintenance you miss the needed commitment and trust. Choosing the right partners for your machine learning project is even harder than for ordinary IT projects, due to the high knowledge factor involved. Some rule of thumbs when selecting partners: Big partners are not always better. With SMB partners who are committed to solve your business challenge with you governance structures are often easier and more flexible. Be aware of vendor lock-ins. Make sure you can change from partners whenever you want. So avoid vendor specific and black-box approaches for machine learning projects. Machine learning is based on learning, and learning requires openness.
Trust and commitment are important factors when selecting partners. Commitment is needed since machine learning projects are in essence innovation projects that need a correct mindset. Use the input of your created solution architecture to determine what kind of partners are needed when. E.g. when your project is finished you need stability and continuity in partnerships more than when you are in an innovative phase.
Risk management#
Running machine learning projects involves risk. Within your architecture it is crucial to address business and projects risks early. Especially when security, privacy and safety aspects are involved mature risks management is recommended. To make sure your machine learning project is not dead at launch, risk management requires a flexible and creative approach for machine learning projects. Of course when your project is more mature openness and management on all risks involved are crucial. To avoid disaster machine learning projects it is recommended to create your:
solution architecture using:
Safety by design principles.
Security by design principles and
Privacy by design principles
In the beginning this slows down your project, but doing security/privacy or safety later as ‘add-on’ requirements is never a real possibility and takes exponential more time and resources.
Development tools#
In order to apply machine learning you need good tools to do e.g.:
Create experiments for machine learning fast.
Create a solid solution architecture
Create a data architecture
Automate repetitive work (integration, deployment, monitoring etc)
Fully integrated tools that cover all aspects of your development process (business design and software and system design) are hard to find. Even in the OSS world. Many good architecture tools, like Arch for creating architecture designs are still usable and should be used. A good overview for general open architecture tools can be found here https://nocomplexity.com/architecture-playbook/.
Within the machine learning domain the de-facto development tool to use is ‘The Jupyter Notebook’. The Jupyter notebook is an web application that allows you to create and share documents that contain live code, equations, visualizations and narrative text. A Jupyter notebook is perfect for various development steps needed for machine learning suchs as data cleaning and transformation, numerical simulation, statistical modelling, data visualization and testing/tuning machine learning models. More information on the Jupyter notebook can be found here https://jupyter.org/ .
But do not fall in love with a tool too soon. You should be confronted with the problem first, before you can evaluate what tool makes your work more easy for you.
Machine learning Frameworks#
Machine Learning frameworks offer software building blocks for designing, training and validating your machine learning model. Most of the time you are only confronted with your chosen machine learning framework when using a high level programming interface. All major FOSS machine learning frameworks offer APIs for all major programming languages. Almost all ‘black magic’ needed for creating machine learning application is hidden in a various software libraries that make a machine learning framework.
In another section of this book a full overview of all major machine learning frameworks are presented. But for creating your architecture within your specific context choosing a machine learning framework that suits your specific use case is a severe difficult task. Of course you can skip this task and go for e.g. Tensorflow in the hope that your specific requirements are offered by simple high level APIs.
Some factors that must be considered when choosing a machine learning framework are:
Stability. How mature, stable is the framework?
Performance. If performance really matters a lot for your application (training or production) doing some benchmark testing and analysis is always recommended.
Features. Besides the learning methods that are supported what other features are included? Often more features, or support for more learning methods is not better. Sometimes simple is enough since you don’t change your machine learning method and model continuously.
Flexibility. How easy is it to switch to another machine learning framework, learning method or API?
Transparency. Machine learning development is a very difficult tasks that involve a lot of knowledge of engineers and programmers. Not many companies have the capabilities to create a machine learning framework. But in case you use a machine learning framework: How do you know the quality? Is it transparent how it works, who has created it, how it is maintained and what your business dependencies are!
License. Of course we do not consider propriety machine learning frameworks. But do keep in mind that the license for a machine learning framework matters. And make sure that no hooks or dual-licensing tricks are played with what you think is an open machine learning Framework.
Speeding up time consuming and recurrent development tasks.
Debugging a machine learning application is no fun and very difficult. Most of the time you spend time with model changes and retraining. But knowing why your model is not working as well as expected is a crucial task that should be supported by your machine learning framework.
There are too many open source machine learning frameworks available which enables you to create machine learning applications. Almost all major OSS frameworks offer engineers the option to build, implement and maintain machine learning systems. But real comparison is a very complex task. And the only way to do some comparison is when machine learning frameworks are open source. And since security, safety and privacy should matter for every use case there is no viable alternative than using a mature OSS machine learning framework.
Programming Tools#
You can use every programming language for developing your machine learning application. But some languages are better suited for creating machine learning applications than others. The top languages for applying machine learning are:
Python.
Java and
R
The choice of the programming language you choice depends on the machine learning framework, the development tools you want to use and the hosting capabilities you have. For fast iterative experimentation a language as Python is well suited. And besides speeds for running your application in production also speed for development should be taken into concern.
There is no such thing as a ‘best language for machine learning’.
There are however bad choices that you can make. E.g. use a new development language that is not mature, has no rich toolset and no community of other people using it for machine learning yet.
Within your solution architecture you should justify the choice you make based upon dependencies as outlined in this reference architecture. But you should also take into account the constraints that account for your project, organisation and other architecture factors that drive your choice. If have e.g. a large amount of Java applications running and all your processes and developers are Java minded, you should take this fact into account when developing and deploying your machine learning application.
Data#
Data is the heart of the machine earning and many of most exciting models don’t work without large data sets. Data is the oil for machine learning. Data is transformed into meaningful and usable information. Information that can be used for humans or information that can be used for autonomous systems to act upon.
In normal architectures you make a clear separation when outlining your data architecture. Common view points for data domains are: business data, application data and technical data For any machine learning architecture and application data is of utmost importance. Not all data that you use to train your machine learning model needs can be originating from you own business processes. So sooner or later you need to use data from other sources. E.g. photo collections, traffic data, weather data, financial data etc. Some good usable data sources are available as open data sources. For a open machine learning solution architecture it is recommended to strive to use open data. This since open data is most of the time already cleaned for privacy aspects. Of course you should take the quality of data in consideration when using external data sources. But when you use data retrieved from your own business processes the quality and validity should be taken into account too.
Free and Open Machine learning needs to be feed with open data sources. Using open data sources has also the advantage that you can far more easily share data, reuse data, exchange machine learning models created and have a far easier task when on and off boarding new team members. Also cost of handling open data sources, since security and privacy regulations are lower are an aspect to take into consideration when choosing what data sources to use.
For machine learning you need ‘big data’. Big data is any kind of data source that has one the following properties:
Big data is data where the volume, velocity or variety of data is (too) great.So big is really a lot of data!
The ability to move that data at a high Velocity of speed.
An ever-expanding Variety of data sources.
Refers to technologies and initiatives that involve data that is too diverse, fast-changing or massive for conventional technologies, skills and infra- structure to address efficiently.
Every Machine Learning problem starts with data. For any project most of the time large quantities of training data are required. Big data incorporates all kinds of data, e.g. structured, unstructured, metadata and semi-structured data from email, social media, text streams, images, and machine sensors (IoT devices).
Machine learning requires the right set of data that can be applied to a learning process. An organization does not have to have big data in order to use machine learning techniques; however, big data can help improve the accuracy of machine learning models. With big data, it is now possible to virtualize data so it can be stored in the most efficient and cost-effective manner whether on- premises or in the cloud.
Within your machine learning project you need to perform data mining. The goal of data mining is to explain and understand the data. Data mining is not intended to make predictions or back up hypotheses.
One of the challenges with machine learning is to automate knowledge to make predictions based on information (data). For computer algorithms everything processed is just data. Only you know the value of data. What data is value information is part of the data preparation process. Note that data makes only sense within a specific context.
The more data you have, the easier it is to apply machine learning for your specific use case. With more data, you can train more powerful models.
Some examples of the kinds of data machine learning practitioners often engage with:
Images: Pictures taken by smartphones or harvested from the web, satellite images, photographs of medical conditions, ultrasounds, and radiologic images like CT scans and MRIs, etc.
Text: Emails, high school essays, tweets, news articles, doctor’s notes, books, and corpora of translated sentences, etc.
Audio: Voice commands sent to smart devices like Amazon Echo, or iPhone or Android phones, audio books, phone calls, music recordings, etc.
Video: Television programs and movies, YouTube videos, cell phone footage, home surveillance, multi-camera tracking, etc.
Structured data: Webpages, electronic medical records, car rental records, electricity bills, etc
Product reviews (on Amazon, Yelp, and various App Stores)
User-generated content (Tweets, Facebook posts, StackOverflow questions)
Troubleshooting data from your ticketing system (customer requests, support tickets, chat logs)
When developing your solution architecture be aware that data is most of the time:
Incorrect and
useless.
So meta data and quality matters. Data only becomes valuable when certain minimal quality properties are met. For instance if you plan to use raw data for automating creating translating text you will discover that spelling and good use of grammar do matter. So the quality of the data input is an import factor of the quality of the output. E.g. automated Google translation services still struggle with many quality aspects, since a lot of data captures (e.g. captured text documents or emails) are full of style,grammar and spell faults.
Data science is a social process. Data is generated by people within a social context. Data scientists are social people who do a lot of communication with all kind of business stakeholders. Data scientist should not work in isolation because the key thing is to find out what story is told within the data set and what import story is told over the data set.
Data Tools#
Without data machine learning stops. For machine learning you deal with large complex data sets (maybe even big data) and the only way to making machine learning applicable is data cleaning and preparation. So you need good tools to handle data.
The number of tools you need depends of the quality of your data sets, your experience, development environment and other choice you must make in your solution architecture. But a view use cases where good solid data tools certainly help are:
Data visualization and viewer tools; Good data exploration tools give visual information about the data sets without a lot of custom programming.
Data filtering, data transformation and data labelling;
Data anonymizer tools;
Data encryption / decryption tools
Data search tools (analytics tools)
Without good data tools you are lost when doing machine learning for real. The good news is: There are a lot of OSS data tools you can use. Depending if you have raw csv, json or syslog data you need other tools to prepare the dataset. The challenge is to choose tools that integrate good in your landscape and save you time when preparing your data for starting developing your machine learning models. Since most of the time when developing machine learning applications you are fighting with data, it is recommended to try multiple tools. Most of the time you experience that a mix of tools is the best option, since a single data tool never covers all your needs. So leave some freedom within your architecture for your team members who deal with data related work (cleaning, preparation etc).
The field of ‘data analytics’ and ‘business intelligence’ is a mature field for decades within IT. So you will discover that many FOSS tools that are excellent for data analytics. But keep in mind that the purpose of fighting with data for machine learning is in essence only for data cleaning and feature extraction. So be aware of ‘old’ tools that are rebranded as new data science tools for machine learning. There is no magic data tool preparation of data for machine learning. Sometimes old-skool unix tool like awk or sed just do the job simple and effective.
Besides tools that assist you with preparing the data pipeline, there are also good (open) tools for finding open datasets that you can use for your machine learning application. See the reference section for some tips.
To prepare your data working with the data within your browser seems a nice idea. You can visual connect data sources and e.g. create visuals by clicking on data. Or inspecting data in a visual way. There is however one major drawback: Despite the great progress made on very good and nice looking JavaScript frameworks for visualization, handling data within a browser DOM still takes your browser over the limit. You can still expect hang-ups, indefinitely waits and very slow interaction. At least when not implemented well. But implementation of on screen data visualisation (Drag-and-Drop browser based) is requires an architecture and design approach that focus on performance and usability from day 1. Unfortunately many visual web based data visualization tools use an generic JS framework that is designed from another angle. So be aware that if you try to display all your data, it eats all your resources(CPU, memory) and you get a lot of frustration. So most of the time using a Jupyter Notebook is a safe choice when preparing your data sets.
Hosting#
Hosting infrastructure is the platform that is capable of running your machine learning application(s). Hosting is a separate block in this reference architecture to make you aware that you must make a number of choices. These choices concerning hosting your machine learning application can make or break your machine learning adventure.
It is a must to make a clear distinguishing in:
Hosting infrastructure needed for development and training and
Hosting infrastructure needed for production
Depending on your application it is e.g. possible that you need a very large and costly hosting infrastructure for development, but you can do deployment of your trained machine learning model on e.g. a Raspberry PI or Arduino board.
Standard hosting capabilities for machine learning are not very different as for ‘normal’ IT services. Expect scalability and flexibility capabilities require solid choices from the start. The machine learning hosting infrastructure exist e.g. out of:
Physical housing and power supply.
Operating system (including backup services).
Network services.
Availability services and Disaster recovery capabilities.
Operating services e.g. deployment,, administration, scheduling and monitoring.
For machine learning the cost of the hosting infrastructure can be significant due to performance requirements needed for handling large datasets and training your machine learning model.
A machine learning hosting platform can make use of various commercial cloud platforms that are offered(Google, AWS, Azure, etc). But since this reference architecture is about Free and Open you should consider what services you to use from external Cloud Hosting Providers (CSPs) and when. The crucial factor is most of the time cost and the number of resources needed. To apply machine learning it is possible to create your own machine learning hosting platform. But in reality this is not always the fasted way if you have not the required knowledge on site.
All major Cloud hosting platforms do offer various capabilities for machine learning hosting requirements. But since definitions and terms differ per provider it is hard to make a good comparison. Especially when commercial products are served instead of OSS solutions. So it is always good to take notice of:
Flexibility (how easy can you switch from your current vendor to another?).
Operating system and APIs offered. And
Hidden cost
For experimenting with machine learning there is not always a direct need for using external cloud hosting infrastructure. It all depends on your own data center capabilities. In a preliminary phase even a very strong gaming desktop with a good GPU can do.
When you want to use machine learning you need a solid machine learning infrastructure. Hosting Infrastructure done well requires a lot of effort and is very complex. E.g. providing security and operating systems updates without impacting business applications is a proven minefield.
For specific use cases you can not use a commodity hosting infrastructure of a random cloud provider. First step should be to develop your own machine learning solution architecture. Based on this architecture you can check what capabilities are needed and what the best way is to start.
The constant factor for machine learning is just as with other IT systems: Change. A machine learning hosting infrastructure should be stable. Also a machine learning hosting infrastructure should be designed as simple as possible. This since the following characteristics apply:
A Machine learning hosting environment must be secured since determining the quality of the outcome is already challenging enough.
Machine learning infrastructure hosting that works now for your use cases is no guarantee for the future. Your use case evolves in future and hosting infrastructure evolves also. At minimum security patches are needed. But a complete hosting infrastructure is not replaced or drastically changed on a frequent basis. The core remains for a long period.
Incorporating new technology and too frequent changes within your hosting infrastructure can introduce security vulnerabilities and unpredictable outcomes.
Changes on your machine learning hosting infrastructure do apply on your complete ML pipeline.
Machine learning hosting infrastructure components should be hardened. This means protecting is needed for accidentally changes or security breaches.
Separation of concerns is just as for any IT architecture a good practice.
So to minimize the risks make sure you have a good view on all your risks. Your solution architecture should give you this overview, including a view of all objects and components that will be changed (or updated) sooner or later. Hosting a machine learning application is partly comparable with hosting large distributed systems. And history learns that this can still be a problem field if not managed well. So make sure what dependencies you accept regarding hosting choices and what dependencies you want to avoid.
Containers#
Understanding container technology is crucial for using machine learning. Using containers within your hosting infrastructure can increase flexibility or if not done well decrease flexibility due to the extra virtualization knowledge needed.
The advantage and disadvantages of the use of Docker or even better Kubernetes or LXD or FreeBSD jails should be known. However is should be clear: Good solid knowledge of how to use and manage a container solution so it benefits you is hard to get.
Using containers for developing and deploying machine learning applications can make life easier. You can also be more flexible towards your cloud service provider or storage provider. Large clusters for machine learning applications deployed on a container technology can give a great performance advantage or flexibility. All major cloud hosting providers also allow you to deploy your own containers. In this way you can start small and simple and scale-up when needed.
Summarized: Container solutions for machine learning can be beneficial for:
Development. No need to install all tools and frameworks.
Hosting. Availability and scalability can be solved using the container infrastructure capabilities.
Integration and testing. Using containers can simplify and ease a pipeline needed to produce quality machine learning application from development to production. However since the machine learning development cycle differs a bit from a traditional CICD (Continuous Integration - Continuous Deployment) pipeline, you should outline this development pipeline to production within your solution architecture in detail.
GPU - CPU or TPU#
Machine learning requires a lot of calculations. Not so long ago very large (scientific) computer cluster were needed for running machine learning applications. However due to the continuous growth of power of ‘normal’ consumer CPUs or GPUs this is no longer needed.
GPUs are critical for many machine learning applications. This because machine learning applications have very intense computational requirements. GPUs are general better equipped for some massive number calculation operations that the more generic CPUs.
A way this process is optimized is by using GPUs instead of CPUs. However the use of GPUs that are supported by the major FOSS ML frameworks, like Pytorch is limited. Only Nvida GPUs are supported by CUDA.
CUDA (Compute Unified Device Architecture) is a parallel computing platform and application programming interface (API) model created by Nvidia. It allows software to use a CUDA-enabled graphics processing of NVIDA. So it is a proprietary standard.
An alternative for CUDA is OpenCL. OpenCL (Open Computing Language) is a framework for writing programs that execute across heterogeneous platforms. OpenCL (https://opencv.org/opencl/ ) has a growing support in terms of hardware and also ML frameworks that are optimized for this standard.
You might have read and heard about TPUs. A tensor processing unit (TPU) is an AI accelerator application-specific integrated circuit (ASIC). First developed by Google specifically for neural network machine learning. But currently more companies are developing TPUs to support machine learning applications.
Within your solution architecture you should be clear on the compute requirements needed. Some questions to be answered are:
Do you need massive compute requirements for training your model?
Do you need massive compute requirements for running of your trained model?
In general training requires far more compute resources than is needed for production use of your machine learning application. However this can differ based on the used machine learning algorithm and the specific application you are developing.
Many machine learning applications are not real time applications, so compute performance requirements for real time applications (e.g. real time facial recognition) can be very different for applications where quality and not speed is more important. E.g. weather applications based on real time data sets.
Storage#
Machine learning needs a lot of data. At least when you are training your own model. E.g. medical, scientific or geological data, as well as imaging data sets frequently combine petabyte scale storage volumes.
Storing data on commercial cloud storage becomes expensive. If not for storage than the network cost involved when data must be connected to different application blocks are high.
If you are using very large data sets you will dive into the world of NoSQL storage and cluster solutions. E.g. Hadoop is an open source software platform managed by the Apache Software Foundation that has proven to be very helpful in storing and managing vast amounts of data cheaply and efficiently.
The bad news is that the number of open (FOSS) options that are really good for unstructured (NoSQL) storage is limited.
Some examples:
Riak® KV is a distributed NoSQL key-value database with advanced local and multi-cluster replication that guarantees reads and writes even in the event of hardware failures or network partitions. Riak is written in erlang so by nature very stable. Use for big data in ml data pipelines (https://riak.com/index.html ).