
Why Free and Open Machine Learning#
Free and Open machine learning is comparable with open source software (FOSS - Free and Open Source Software). But openness for machine learning requires more than open source software alone. So we advocate for using Free and Open machine learning.
The term open source software (OSS) means FOSS in this publication. Freedom is important for free and open machine learning. ‘Open source software’ is sometimes also called “Free software”, “libre software”, “Free/open source software (FOSS or F/OSS)”, and “Free/Libre/Open Source Software (FLOSS)”. But the term “Free software” has been sometimes misinterpreted as meaning “no cost”, which is not the intended meaning. It is all about Freedom, so a better term would have been to call it Freedom Software. So ‘Free’ open source software (FOSS) refers to freedom, not price. This also applies for Free and Open Machine Learning. Free refers to freedom.
The Freedom part makes a key difference in making sure machine learning technology and all related aspects, secure freedom in a sustainable way.
FOSS machine learning is crucial for everyone. In our view machine learning technology must be inclusive for all. This means that besides using FOSS machine learning frameworks like Tensorflow all aspects must be open and transparent. In this way machine learning becomes a real open and inclusive technology that can be used for the advantage of everyone. And everyone should be able to experiment, play and create a new machine learning application. Without major obstacles in terms of cost for technology usage or hardware required.
Free and Open machine learning means that everyone must be able to develop, test, play and deploy machine learning based solutions. Large investments should not be needed for using and applying machine learning. So not only companies or people who can afford the enormous investments needed in specialized GPU hardware benefit of machine learning technology, but everyone can benefit. In this way everyone is able to create meaningful applications to create a better world. Without making enormous investments upfront.
FOSS machine learning involves more than FOSS software. The following aspects are needed for real Free and Open Machine Learning:
FOSS Machine learning software (Free and Open Source software)
Open Data
Open Algorithms (Transparent machine learning algorithms)
Open Architectures
Open Science
These aspects are the core pillars of Free and Open Machine Learning.
Open Source (FOSS)#
Free and open-source software (FOSS) is software that can be classified as both free software and open-source software. FOSS is an inclusive term that covers both free software(FLOSS) and open-source software(OSS).
Open Source is an approach for the design, development, and distribution of new products & knowledge offering practical accessibility to its source. Real open source solutions have a license that is approved by the Free Software Foundation (FSF) (https://www.fsf.org/) or the Open Source Initiative (OSI) foundation (https://opensource.org/). Open source is all about collaboration and Freedom. Collaboration is key for developing, applying and using machine learning functionality.
Software is free software if users have four essential freedoms:
The freedom to run the program as you wish, for any purpose.
The freedom to study how the program works, and change it so it does your computing as you wish. Access to the source code is a precondition for this.
The freedom to redistribute copies so you can help others.
The freedom to distribute copies of your modified versions to others. By doing this you can give the whole community a chance to benefit from your changes. Access to the source code is a precondition for this.
Open Source Software(FOSS) is the standard for machine learning algorithms. However using open source software is still a new and innovative concept for many companies. If you really want to benefit from new machine learning software you must go for a solid FOSS machine learning ecosystem. This makes you flexible, independent and you can still use thousands of consultancy firms and (Cloud)hosting companies that can help you, or are willing to provide hosting facilities.
A transition towards FOSS software can already be very hard and can be disruptive for many companies. It takes the right mindset, attitude and culture within a company. Applying machine learning for real business cases is also complex and challenging. So taking advantage of machine learning requires the right innovative mindset. Using machine learning without using the benefits that come with the FOSS ecosystems of choice, is like learning to swim without hitting the water. So hit the water as soon as possible, after a while you see and use the benefits.
Machine learning applications are expensive to develop and to adopt. This accounts for the development process itself but also good skilled professional IT engineers and scientists are expensive. But it accounts also for the needed infrastructure and other software resources needed to develop meaningful applications for your business. This means that currently big firms like Google, IBM, Microsoft, Facebook and Amazon are at the front of the queue and smaller counterparts get left behind. But most of the scientific knowledge of machine learning technology and a lot of software is open and freely available. The core concepts of the technique behind machine learning is crucial to known before starting business projects. Machine learning for real use cases requires adjustments and continuous tweaking, which is hard when you are using inflexible black-box solutions.
FOSS developments in the machine learning field are absolutely no hobby projects. Almost all major FOSS machine learning developments are backed by small or large companies(e.g. Google, Microsoft, Facebook, Uber) active in the deep learning ecosystem. Also many great FOSS machine learning frameworks are backed by research groups of universities or research communities organized by universities. Small machine learning FOSS projects are often developed by PhD researchers and are supported by a strong scientific foundation.
A focus on open source (FOSS) software for applying machine learning for real is crucial. FOSS machine learning applications and frameworks have the following benefits:
Create solutions software faster, better and with less friction. You can adjust what you want without limitations.
Lower cost for creating your first pilot project. Mind: Your first attempts will fail. And the faster your pilot projects fail, the better. This since applying the new machine learning capabilities requires a learning curve. Technical, but also for the organization and business side point of view.
Flexibility and changeability.
No vendor lock ins. Of course the machine learning cloud offerings of the major tech companies are great (Azure ML, IBM Watson, Amazon, Google etc). But playing around without any strings attached and limitations set for you gives you a head start.
Software is less dependent on a single company or software developer. Healthy FOSS projects have a large ecosystem of companies and independent contributors that maintain the code and preserve the quality.
Software is often more compatible with a wide range of other open systems. Most FOSS projects build upon open platforms. Also good ML frameworks want to be used and improved. So open and easy integration with other systems and tools is often built-in.
Open code is better science. The field of machine learning is still improving. Many researchers work on algorithms and improvements. Open code enables open science. Community input and feedback increases the quality. Also openness means that when papers of researchers are published everyone can inspect, use and improve the code that was developed. This openness enforces quality.
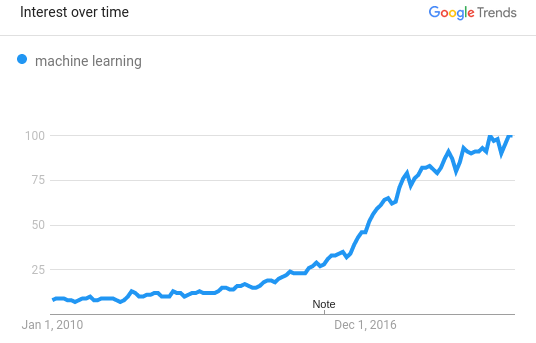
FOSS machine learning and machine learning in general is very popular. See e.g. the diagram below which shows a view of the increase in google searches for the recent decade. You should have very strong arguments, also from a business perspective. This is because investments for real world application have always have business risks. Choosing a commercial black box solution often increases business risks and mitigation of risks is harder. E.g. security and privacy risk mitigation is hard with blackbox solutions.
All IT companies advertise with machine learning powered software products nowadays. This also means that existing software that has been sold for decades is now re-branded with the new machine learning buzz words. Also terms like cognitive, artificial intelligence (AI) powered and data driven are used to sell you old solutions using this new trend. You can easily be fooled since massive marketing efforts (time, money, material) are invested to sell old buggy solutions as new innovative machine learning powered solutions. In reality black box solutions from small or large vendors that seems too good to be true for your use case, are almost always based on fads. This is why you should be very suspicious when using cloud based machine offerings that offers you instant new business and customers. Make sure to do a fast and cheap hands on innovation project first. Evaluate if and how your business use case can really benefit from machine learning. If a new machine learning solution looks too good to be true, be aware.
To use machine learning for real business applications you should use and reuse good FOSS tools, frameworks and knowledge available. But you should also take the quality aspects, technical and non-technical, that comes with a machine learning framework choice into account.
When using machine learning FOSS solutions you can and should inspect the working and evaluate all risks involved. By using a FOSS solution you can ask every IT company or consultant with the right skills to audit the application. Because in the end: When security, safety or privacy of your customers is at risk, you are accountable.
Open data#
Free and Open machine learning does not only need FOSS software, but also open data sets. Data is one of the most important aspects for making machine learning work. Without data and open transparent insights in the various quality aspects of the data, machine learning is not open.
Without data machine learning is not possible. FOSS Machine learning systems need open data to function. To function properly the following is needed for FOSS machine learning:
Open data. Open data is data that can be freely used, re-used and redistributed by anyone.
Lots of data. Training machine learning models requires large amounts of data.
Data variety. For good training sets variety in data used is crucial. Else the bias problem turns up directly.
Data veracity. This means the truthfulness of data.
Trust in the outcome of applications powered by machine learning technology is only possible when the input data is fully available.
Open and reusable quality datasets are crucial for creating machine learning driven applications. If you use a trained machine learning algorithms, it is crucial that you have full insight in the origin of all training data. How it was collected, filtered and used.
Creating a data set to test and develop machine learning algorithms is hard and time consuming. Many current machine learning algorithms are developed and verified by using open data sets. In https://en.wikipedia.org/wiki/List_of_datasets_for_machine-learning_research a short overview can be found of various data sets used for scientific machine learning research.
Free and open machine learning means that everyone should be able to access and use data that is used to train machine learning applications. So Google, Facebook and many other companies who donate a lot of machine learning knowledge and frameworks in the open source domain rarely release datasets that are used for their fantastic commercial machine learning offerings. Not knowing details about datasets, especially for live saving systems that are powered using machine learning technology, means verification of claims is impossible. There are can also be large privacy risks involved, since training machine learning algorithms requires large datasets. Seldom do people give permission for using their valuable data for developing applications that are not beneficial for them. E.g. why should a government use your data in order to develop an application that is not in your interest.
Data collection and data preparation is a major bottleneck in open machine learning. As machine learning becomes more widely used, it is important to acquire large amounts of open data. Especially for state-of-the-art neural networks.
In the ideal FOSS machine learning world all non-personal information is open and free for everyone to use, build on and share. So every organisation, small or big, can create new machine learning applications.
Preparing data to be used for training machine learning models is still very time consuming and cost intensive. So most business machine learning applications created make use of already trained models. E.g. for speech or image recognition. But for your unique use cases: training your own machine learning model is crucial.
Machine learning involves data, so you and your your business should act based on leading data ethics principles. Some obvious data ethics principles are:
Foresighted responsibility. So think ahead or imagining or anticipate what might happen in the future.
Use open data.
Be transparent.
Respect data privacy regulations and laws (e.g. EU GDPR)
Open Science and open algorithms#
Machine learning is a challenging science. Many researchers on universities worldwide are working to develop new knowledge for solving a range of complex problems.
Universities are funded by taxpayers. So in an ideal world everyone should benefit from knowledge developed. Also almost all knowledge developed is based on work developed earlier by others. This is how science works. We build upon knowing of others to develop new knowledge and insights.
Open science represents an approach to the scientific process based on cooperative work and new ways of diffusing knowledge by using digital technologies and new collaborative tools. This idea captures a systemic change to the way science and research have been carried out for the latest fifty years: shifting from the standard practices of publishing research results in scientific publications towards sharing and using all available knowledge at an earlier stage in the research process.
Developing machine learning knowledge using open science means that publications, data, results, and software is accessible without borders for everyone to learn and build upon. Key pillars of open science important that are for open machine learning are:
Open Data
Open source software
Open access
Everyone should be able to validate claims, inspect algorithms used and can created and read machine learning experiments. All without large upfront costs. Transparency is needed for trust. This also accounts for machine learning applications, algorithms and frameworks used.
For real open machine learning applications providing real transparency in terms of explaining how results are created is a complex problem. This is a direct result of how some types of machine learning algorithms work. The current generation of machine learning systems offer tremendous benefits, but their effectiveness is limited by the machine’s inability to explain its decisions and actions to users. The so called ‘explainable’ machine learning tools will be essential for users to understand and trust machine learning applications.
Only when the basic principles for open science are followed, trust in machine learning algorithms and software frameworks is possible.
The key of machine learning is smart algorithms. Algorithms that operate as “black boxes” should never be trusted. Fighting against your government is very difficult if you have no insight in the used algorithms. Open algorithms developed in an open scientific environment are key for trust.
FOSS machine learning with the use of open algorithms is needed to prevent a “black box society”. That is a society” in which key moments of our lives are mediated by unknown, unseen, and arbitrary algorithms. Open algorithms and algorithmic accountability is a way to stop this pattern. An open algorithm makes it possible for anyone to analyse.
Open architectures#
Architecture is a minefield. Architecture is not by definition high level and sometimes relevant details are of the utmost importance. It is not strange that the added value of architecture and architects within large companies and projects is under heavy pressure due to architecture failures at large and the emergence of agile approaches to solve business IT problems.
Architecture (business, information, application and technical) of digital systems have an enormous impact on the products we use daily. For developing and creating large complex systems you still need an architecture. Developing a solid solution architecture and creating solutions by working using an agile method should reinforces each other.
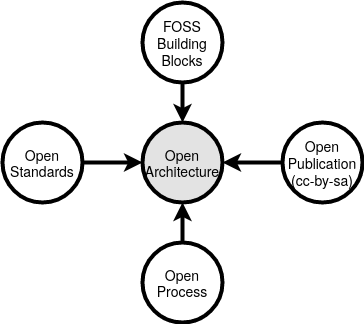
Open architectures should be concentrated around the following pillars:
Solutions should be created using FOSS system building blocks.
The created architecture blueprint is available for everyone. so use a friendly (creative commons) license.
The architecture is developed in an open process in which everyone participates to improve the architecture. E.g. also customers, business stakeholders other stakeholders that will be impacted by the architecture design in future. Borders that hinder participation should be removed.
The architecture is based around good usable standards that anyone can and may implement, use and improve. Unfortunate not all open standards are really open and usable.
Green ML#
Applying new technology brings new responsibilities. Computations power needed for deep learning research have been doubling every few months. Machine learning computations can have a very large carbon footprint. This is a results of the way most algorithms are designed.
Almost all machine learning algorithms give only good results when large amounts of data are used and an enormous number of calculations are performed. Computers do use a lot of energy when calculations at large are performed.
Ironically, deep learning was inspired by the human brain, which is remarkably energy efficient. Moreover, the financial cost of the computations can make it difficult for academics, students, and researchers, in particular those from emerging economies, to engage in deep learning research.
Green machine learning means machine learning that is optimized to minimize resource utilization and environmental impact. This can be done by data center resource optimization, balancing training data requirements versus accuracy, choosing less resource intensive models or in some cases transfer learning versus new models.
Besides the cost factor, green machine learning is an important factor for Free and Open machine learning since the benefits machine learning can bring should not harm the environment of all living cells that have no direct relationship with your machine learning application.
The Freedom to use the powerful machine learning technology should not limit the freedom to live in good health for others. So green ML is a difficult but important aspects for machine learning developments. So chose algorithms that perform well without weeks of calculation on datasets. Or make sure expensive and time consuming calculations can be reused by others in an easy way.