
What is machine learning#
To understand the basic principles of machine learning you do not need to have a PhD in computer science or have done a complex mathematical or technological study with a Master of Science (MSc) degree. Machine learning should be open and beneficial for everyone. So it is important that everyone can learn and understand the basics and the underlying principles of machine learning.
This section outlines common used terms that are used within the machine learning field. If you are short on time and want to know what the machine learning buzz is all about: This is the section you should read!
Before introducing terms and definitions: Be aware that no unified de-facto definition of machine learning exists. So be aware that when people are writing and talking about ‘machine learning’ they can be talking about totally different things and subjects. The machine learning (ML) label is often misused and intertwined with artificial intelligence (AI).
Investments in machine learning by large commercial companies are still growing. But a lot of documentation that is freely available on machine learning, especially some documents created by commercial vendors, is biased. In the reference section of this book you find a collection of open access resources for a more in depth study on various machine learning subjects. Be aware that also open access publications are not free from commercial interest. So also open access publications on machine learning are not always objective and free from bias.
Attention
Be aware of facts and fads when reading machine learning papers and books. Always be critical.
This section outlines essential concepts surrounding machine learning more in depth.
ML, AI, LLM and NLP: What is what?#
Machine Learning (ML) and Artificial Intelligence (AI) are terms that are crucial to know when creating machine learning driven solutions. But also the term NLP (Natural language processing) is a term that is crucial for understanding current machine learning application that are created for speech or text. E.g. for bots which you can converse with instead of humans.
So let’s start with a high level separation of common used terms and their meaning:
AI (Artificial intelligence) is concerned with solving tasks that are easy for humans but hard for computers.
ML (Machine learning) is the science of getting computers to act without being explicitly programmed. Machine learning (ML) is basically learning through doing. Often machine learning is regarded as a subset of AI.
NLP (Natural language processing) is the part of machine learning that has to do with language (usually written). NLP concepts are outlined more in depth in another chapter of this book.
LLMs (Large Language Models) are a fundamental approach for achieving cognitive intelligence in the field of natural language processing (NLP). LLMs have revolutionized natural language processing by achieving state-of-the-art performance across various tasks. LLMs are language models with many parameters, and are trained with self-supervised learning on giant data sets (text, video, speech and more) . The largest and most capable LLMs are generative pretrained transformers (GPTs).
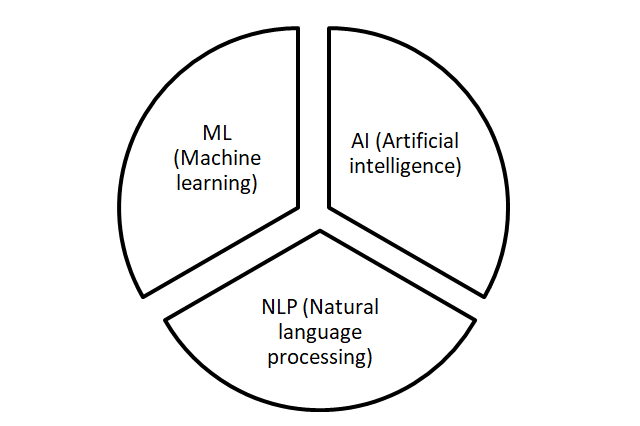
A clear distinction between AI and ML is hard to make. Discussions on making a clear distinguishing are often a waste of time and are heavily biased. For this publication we use the term machine learning (ML), since machine learning can be brought down to tangible hard mathematical algebra, software implementations and tangible applications. Philosophical discussions on questions ‘what is intelligence?’ are mostly related to AI discussions.
At its core, machine learning is simply a way of achieving AI. Machine learning can be seen as currently the only viable approach to building AI systems that can operate in complicated real-world environments.
A few other definitions of artificial intelligence:
A branch of computer science dealing with the simulation of intelligent behaviour in computers.
The capability of a machine to imitate intelligent human behaviour.
A computer system able to perform tasks that normally require human intelligence, such as visual perception, speech recognition, decision-making, and translation between languages.
There are a lot of ways to simulate human intelligence, and some methods are more intelligent than others. AI raises questions on the philosophical spectrum, like ‘What is intelligence?’, ‘How do we measure intelligence?’ AI also gives a lot of fuel for ethical discussions like:
Should AI driven machine learning be a legal entity?
How do we prevent AI machines to kill human life, since AI machines will be ‘smarter’ than human intelligence ever will be.
These ethical questions should not be neglected. In the section ‘ML in Business problems’ a deep dive in the ethical issues for applying machine learning for business use cases is given.
Machine Learning is the most used current application of AI based around the idea that we should really just be able to give machines access to data and let them learn for themselves.
The paradigm shift: Creating smart software#
To really understand machine learning a new view on how software can be created and how it works is needed. Most of our current computer programs are coded by using requirements, logic and design principles for creating good software. E.g. When you add an item to your shopping cart, you trigger an application component to store an entry in a shopping cart database table. So humans create an algorithm to solve a problem. Algorithms are a sequence of computer instructions used to solve a problem.
Many real world problems aren’t easy to solve. A good solution requires knowledge of the context and a lot of domain knowledge built from experience. The domain knowledge needed is often difficult to identify exactly.
Determining the exact context of a car in traffic and in order to make a decision within milliseconds to go left or right is a very hard programming challenge. It takes you decades and you will never do it right. This is why a paradigm shift in creating software for the next phase of automation is needed.
Programming computers the traditional way made it possible to put a man on the moon. To break new barriers in automation in our daily lives and science, requires new ways of thinking about creating intelligent software. Machine learning is a new way to ‘program’ computers. When a programming challenge is too large to solve with traditional programming methods (requirements collection, decision rules collection, etc) a program for a computer should be ‘generated’. Generated based on some known desired output types. But knowing all desired output types in front for a problem solution is often impossible. So your new machine learning ‘program’ will get it wrong sometimes. Large amounts of input data increases the quality of the generated prediction model. In the old traditional paradigm called ‘the program’.
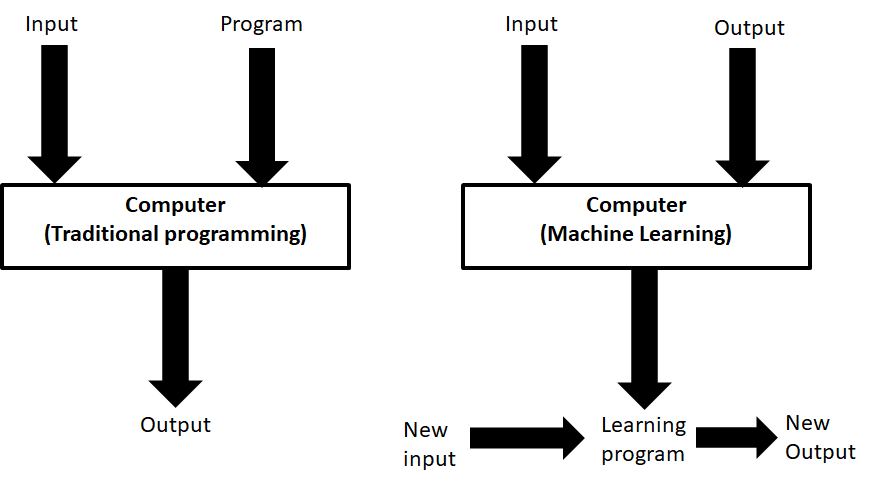
Difference between general programming and (supervised) machine learning.
In essence machine learning makes computers learn the same way people learn: Through experience. And just as with humans, algorithms exist that makes it possible to make use of learned experience of other computers to make your machine learning application faster and better.
The essence of machine learning is that a model is constructed based on so called training data. In machine learning, learning algorithms, so not computer programmers, create the rules.
The term machine learning model refers to the model artefact that is created by the training process. With this machine learning model it is now possible to create meaningful output based on new input. At least when the trained model is functioning as intended. In the figure below another view of the essence of the working of machine learning.
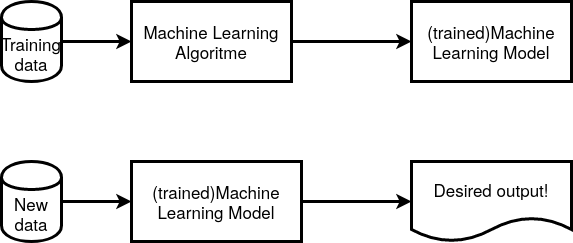
What is a machine learning model#
A machine learning model consists of numbers. Most of the time a very large amount of numbers. With the danger of getting into math: A machine learning model is a collection of numbers that are presented in a large multi dimensional matrix.
A model in the machine learning world is not different than any other mathematical model that presents some knowledge or (trained)information. It is just a large amount of numbers. So you need the algorithm to use it.
A model of data (plain numbers) can be used for any number of things. E.g.:
To simply tell you about the behaviour of your data. For example, the mean is a model. If you imaging picking numbers at random from 1-10, a mean does summarize some useful information about your data. The same with the median and the variance. These are extremely lossy models, but they are models of your data.
To classify data. Say you’ve trained a classifier that classifies whether a photo contains a cat or not. That classifier concisely summarizes your data as “cat photo” or “non-cat photo.”
An efficient way to represent data for some other task. For example, you might generate paraphrases of a documents and model this as vector data. You can then use this model to classify the unique author of the text. So if you present a new document to this model using a simple machine learning algorithms the model gives you a number that indicates if this new document is from the same author or not.
Statistics is not machine learning#
Statistics is not machine learning. So let repeat this one more time:Statistics is not machine learning. But the truth is that statistics and machine learning are intertwined and can not be seen separated. So for a good understanding and basic knowledge of machine learning, basic statistics knowledge is important.
The question ‘What’s the difference between Machine Learning and Statistics?’ is a questions that occurs often and leads to heavy discussion among scientists. To get it straight: A very clear separation between machine learning and statistics is hard to make. Machine Learning is however more a hybrid field than statistics. Some answers on this question are:
Machine learning is essentially a form of applied statistics.
Machine learning is glorified statistics.
Machine learning is statistics scaled up to big data.
Machine learning improves a model by learning using data, where a statistical model is not automatically improved feeding it more data.
Statistics emphasizes inference, whereas machine learning emphasized prediction.
Of course all answers are a bit true. With Machine Learning insights improve based when using more data. Using pure statistical models, learning and improving is not automatically guaranteed when more data is added. Statistical and machine learning methods and the reasoning about data do have a large overlap, but the purpose of using statistics is often very different than when machine learning is used.
Machine Learning can be defined as:
Machine learning is a field of computer science that uses statistical techniques to give computer systems the ability to “learn” with data, without being explicitly programmed. (source Wikipedia) So for example progressively improve learning performance for a specific task based on data input.
The underlying algorithms used for machine learning are essentially based around statistics methods. Machine learning is similar to the concepts around data mining. An algorithm attempts to find patterns in data to classify, predict, or uncover meaningful trends. Machine learning is often only useful if enough data is available. And if the data has been prepared correctly. So despite the promises of machine learning, when you want to apply machine learning you always have a data challenge. Getting good and large amounts of data that is usable for input of a machine learning algorithm is not a simple problem to solve. Not only getting enough quality data, but also managing (storing, processing etc) the retrieved data is hard. Most of the time the storage and performance aspect are the easiest problems to solve regarding data. Getting good quality data is often very hard.
For machine learning, four things are needed:
Data. More is better.
A model of how to transform the data.
A loss function to measure how good the model is performing.
An algorithm to tweak the model parameters such that the loss function is minimized
Machine learning algorithms discover patterns in data, and construct mathematical models using these discoveries.
Overview machine learning methods#
Whenever you are confronted with machine learning it is good to known that different methods, and thus approaches, exist.
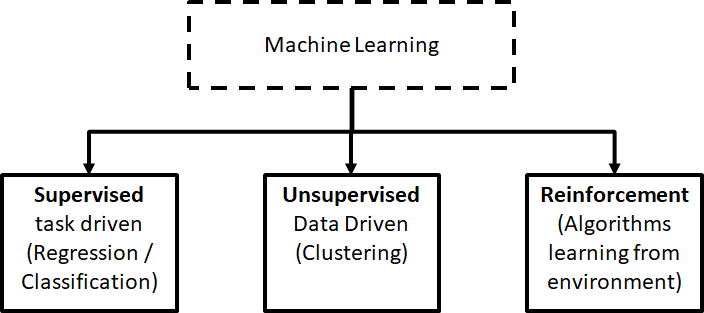
At the highest level, machine learning can be categorized into the following core types:
Supervised learning.
Unsupervised learning.
Reinforcement Learning.
Supervised Learning#
Supervised learning addresses the task of predicting targets given input data.
Most practical business machine learning solutions use supervised learning. Supervised learning encompasses approaches to satisfy the need to classify things into categories, known as classification. It also includes approaches to address the need to provide variable real-value solutions such as weight or height known as regression.
With supervised learning the learning algorithm is given labelled data and the desired output. For example, pictures of cats labelled “cat” help the algorithm to identify the rules to classify pictures of cats.
Unsupervised Learning#
The goal of this type of learning is to model data and uncover trends that are not obvious in its original state. The input data given to the learning algorithm is unlabelled, and the algorithm is asked to identify patterns in the input data.
This type of learning is used to learn about data. Unsupervised learning methods are suited for unlabelled data. It is used is to find patterns where the patterns are still unknown. Unsupervised learning seems attractive since it does not require a lot of hard work of data cleaning before starting. However there are also serious challenges when applying unsupervised learning.
To name a few:
Without a possibility to tell the machine learning algorithm what you want (like in classification), it is difficult to judge the quality of the results.
You have to select a lot of good examples from each class while you are training the classifier. If you consider classification of big data that can be a real challenge.
Training needs a lot of computation time, so do the classification.
Unsupervised learning is more subjective than supervised learning, as there is no clear goal set for the analysis, such as prediction of a response.
The order of the data can have an impact on the final results.
Rescaling your datasets can completely change results.
In machine learning there is no single algorithm that works best for every problem. This is especially relevant for supervised learning (i.e. predictive modelling). So machine learning is a bit like cooking. You have to try some things before it fits your taste.
Reinforcement learning (RL)#
Reinforcement Learning is close to human learning. Reinforcement learning differs from standard supervised learning in that correct input/output pairs are never presented, nor sub-optimal actions explicitly corrected. Instead the focus is on performance. Reinforcement learning can be seen as learning best actions based on reward or punishment.
Reinforcement learning (RL) is learning by interacting with an environment. An RL agent learns from the consequences of its actions, rather than from being explicitly taught and it selects its actions on basis of its past experiences (exploitation) and also by new choices (exploration), which is essentially trial and error learning.
In reinforcement learning (RL) there is no answer key, but your reinforcement learning agent still has to decide how to act to perform its task. In the absence of existing training data, the agent learns from experience. It collects the training examples (“this action was good, that action was bad”) through trial-and-error as it attempts its task, with the goal of maximizing long-term reward.
RL methods are employed to address the following typical problems:
The Prediction Problem and
the Control Problem.
Deep learning (DL)#
Deep Learning(DL) is an approach to machine learning which drives the current hype wave of self driving cars and more.
Deep Learning (DL) is a type of machine learning that enables computer systems to improve with experience and data. Deep learning is a subfield of machine learning.
Deep learning uses layers to progressively extract features from the raw input. For example, in image processing, lower layers may identify edges, while higher layers may identify the concepts relevant to a human such as digits or letters or faces.
Deep learning models can achieve excellent accuracy, sometimes exceeding human-level performance. Most deep learning methods use neural network architectures, which is why deep learning models are often referred to as deep neural networks.
AutoML#
Of course every technology evolves continuously. So when you have mastered a bit of the machine learning concepts you will be faced with more and more machine learning innovations. The big next promising thing for machine learning is automated machine learning in short autoML.
AutoML can be defined as: the automated process of algorithm selection, hyperparameter tuning, iterative modelling, and model assessment. AutoML accelerates the model building process, the time consuming ‘human’ part within ML.
So with the current machine learning we have:
Solution = ML expertise + data + computation
With AutoML the challenge is to turn this into:
Solution = data + 100X computation
Transformers#
The Transformer is a new deep learning model introduced in 2017. Transformers are primarily used in the field of natural language processing (NLP).
Since their introduction, Transformers have become the model of choice for tackling many problems in NLP, replacing older recurrent neural network models such as the long short-term memory (LSTM). Since the Transformer model facilitates more parallelization during training, it has enabled training on larger datasets than was possible before it was introduced. This has led to the development of pretrained systems such as BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer), which have been trained with huge general language datasets, and can be fine-tuned to specific language tasks. Transformers are key in understanding LLMs.
Tip
A nice introduction on how transformers work is available in Transformers from Scratch note: This explanation is in depth, so with mathematical formulas.
Simple ML/AI Topology#
The ML/AI is flooded with terms and hypes. Using a simple conceptual model that makes sense helps.

Artificial General Intelligence (AGI)#
Artificial General Intelligence (AGI) is a hypothetical type of AI that possesses human-level intelligence. An AGI could perform any intellectual task that a human being can, including learning, reasoning, problem-solving, and understanding language. AGI is still largely theoretical, and there’s debate about when or even if it ever will be achieved.
Artificial Intelligence#
Artificial intelligence (AI) is a broad field of computer science that aims to create machines capable of performing tasks that typically require human intelligence. This includes things like learning, problem-solving, decision-making, and understanding language. The only tangible and possible way for AI applications is driven by ML (Machine Learning). I prefer to use the term ML instead of AI to avoid discussions on what ‘intelligence’ is.
Machine Learning#
Machine learning (ML) is a subset of AI that focuses on enabling machines to learn from data without being explicitly programmed. Instead of relying on hard-coded rules, so called traditional software programs, ML algorithms identify patterns in data and use those patterns to make predictions or decisions.
Deep Learning (DL)#
Deep learning is a specialized area within machine learning that utilizes artificial neural networks with multiple layers to analyze data and extract meaningful insights.
Generative AI (GenAI)#
Generative AI (GenAI) is a type of artificial intelligence that focuses on creating new content, rather than just analyzing or acting on existing data.
Large Language Models (LLMs)#
LLMs are a type of generative AI. LLMs are models that are trained on massive amounts of language data from various sources. Often various ML techniques are used for creating LLMs models. E.g. many NLP techniques are used to create LLM models for speech or text.
LLMs are based on a theoretical concept called transformer model. This transformer model can encode and decode data so that the LLM can analyze and understand text by paying attention to how words and phrases relate to each other in a sequence.
Other common terms used in the ML world#
Within the world of machine learning you read and hear about concepts and terms as networks, deep learning, reinforcement learning and more. Many of these terms are derived from years of scientific progress and discussions. This sections explains some common ML terms.
Data science#
Data science can be defined as:
The practice of, and methods for, reporting and decision making based on data.
So Data science is a umbrella term for several disciplines (technical and non technical) that deal with data. Even storing data in a retrievable way is a real science with many pitfalls.
Generative model#
A Generative model can be defined as:
A model for generating all values for a phenomenon, both those that can be observed in the world and “target” variables that can only be computed from those observed
Neural networks (NNs)#
Neural networks (NNs) can be defined as:
An ANN is based on a collection of connected units or nodes called artificial neurons, which loosely model the neurons in a biological brain. Each connection, like the synapses in a biological brain, can transmit a signal to other neurons. An artificial neuron that receives a signal then processes it and can signal neurons connected to it. The “signal” at a connection is a real number, and the output of each neuron is computed by some non-linear function of the sum of its inputs. The connections are called edges. Neurons and edges typically have a weight that adjusts as learning proceeds. The weight increases or decreases the strength of the signal at a connection. Neurons may have a threshold such that a signal is sent only if the aggregate signal crosses that threshold. Typically, neurons are aggregated into layers. Different layers may perform different transformations on their inputs. Signals travel from the first layer (the input layer), to the last layer (the output layer), possibly after traversing the layers multiple times. (source Wikipedia)
The ‘thinking’ or processing that a brain carries out is the result of these neural networks in action. A brain’s neural networks continuously change and update themselves in many ways, including modifications to the amount of weighting applied between neurons. This happens as a direct result of learning and experience.
NN are can be regarded as statistical models directly inspired by, and partially modelled on biological neural networks. They are capable of modelling and processing non-linear relationships between inputs and outputs in parallel. The related algorithms are part of the broader field of machine learning, and can be used in many applications.
Features (also called attributes): Properties of an data object to train a machine learning system. Think of features as number of colours in your street,the number of leafs on a tree, or the size of a garden. A smart selection of features is crucial to train a machine learning system.
Vision#
A lot of machine learning applications work on vision. But vision for computers is different from vision for humans. Humans can not see without thinking. And when we see something our mind is continuously playing with us.
Vision for computers can be defined as:
The ability of computers to “see” by recognizing what is in a picture or video.
Speech#
One of the great things we can do with computers to create applications that transfer words to speech or when we need a lot of data transfer speech to data. Great progress has been made on automatically analysing conversations without human intervention needed.
Speech:
the ability of computers to listen by understanding the words that people say and to transcribe them into text.
Language#
Understanding each other is hard. But this is typical a field where machine learning applications, mainly NLP driven have made great progress using (new)machine learning techniques and technologies.
A definition of language as used within the machine learning field:
The ability of computers to comprehend the meaning of the words, taking into account the many nuances and complexities of language (such as slang and idiomatic expressions).
Knowledge#
Defining knowledge is hard, but crucial for many machine learning applications. An attempt to define knowledge in the context of machine learning:
Knowledge:
The ability of a computer to reason by understanding the relationship between people, things, places, events and context.
Overfitting#
Overfitting means the model fits the parameters too closely with regard to the particular observations in the training dataset, but does not generalize well to new data. Most of the time the model is too complex for the given training data.
Program synthesis#
Program synthesis can automatically produce software code. Its applications range from web automation, hardware security, operating system extensions, programming for non-programmers, authoring of SQL queries, configuration management, automatic code translation, and superoptimization.