
ML implementation challenges#
Machine learning is a technology that currently comes with some special challenges. This section outlines the most important challenges you hit when you start using machine learning for real.
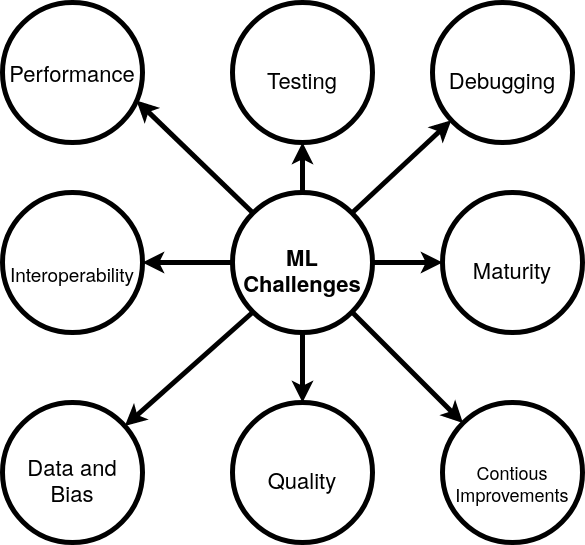
Performance#
Machine learning is amazingly slow. So before you use cloud services for your machine learning performance challenges, it is wise to do some experiments on a simple laptop. After you have a feeling of your model and the main performance bottlenecks than using clusters of advantaged GPUs offered by all Cloud providers is more effective. Also from a cost perspective.
Special machine learning hardware is at its infancy. Even faster systems and wider deployment lead to many more breakthroughs across a wide range of domains.
Many ML OSS software solutions are created in the Python programming language. Python is considered ‘slow’ and hard to parallelize. However many solutions exist to solve this problem. The most important OSS machine learning software solutions are by design capable to run on complete clusters of GPU (Graphical Processor Units). Scalability over GPU has proven to be more efficient for machine learning calculations than using more CPUs. This is because GPUs are by design more suited for the complex calculations needed to perform than CPUs. GPUs are better for speeding up calculations that are needed for distributed machine learning algorithms. A GPU core is designed for handling multiple tasks simultaneously. A core for a GPU is simpler than a CPU core, but a GPU has many more cores than a CPU.
New CPUs are being developed especially for machine learning algorithms. E.g. Google is developing Tensor Processing Units (TPU’s) to speed up the machine learning calculations. Of course this TPU’s are optimized for Google’s tensorflow software. But since this software is OSS everyone can take advantages if needed, since Google offers TPU’s in their Cloud offerings. Of course Microsoft and other big Cloud providers are also developing their specialized machine learning processing units.
Performance for training machine learning solutions is not always simple to solve. This is due to the fact that in essence training machine learning models means doing mass matrix calculations. Despite the fact that Python is a good choice for machine learning, processing large calculations can be slow. So optimization can be needed to speed up pre-processing during the data preparation phase. The good news is that since Python is becoming the de-facto standard for machine learning almost all problems are known and often already solved.
Testing machine learning models#
Automated testing is a large part of software development. Unfortunately performing testing on software and infrastructure is still a mandatory requirement for solid ML projects. Once a project reaches a certain level of complexity, the only way that it can be maintained is if it has a set of tests that identify the main functionality and allow you to verify that functionality is intact. Without automatic tests, it’s nearly impossible to identify where errors are occurring, and to fix those errors without causing further problems.
Testing should be done on:
Data (training data)
Infrastructure
Software QA aspects. In fact all ISO QA factors should be evaluated.
Security, Privacy and safety aspects.
Overview ISO Quality Standard(25010)
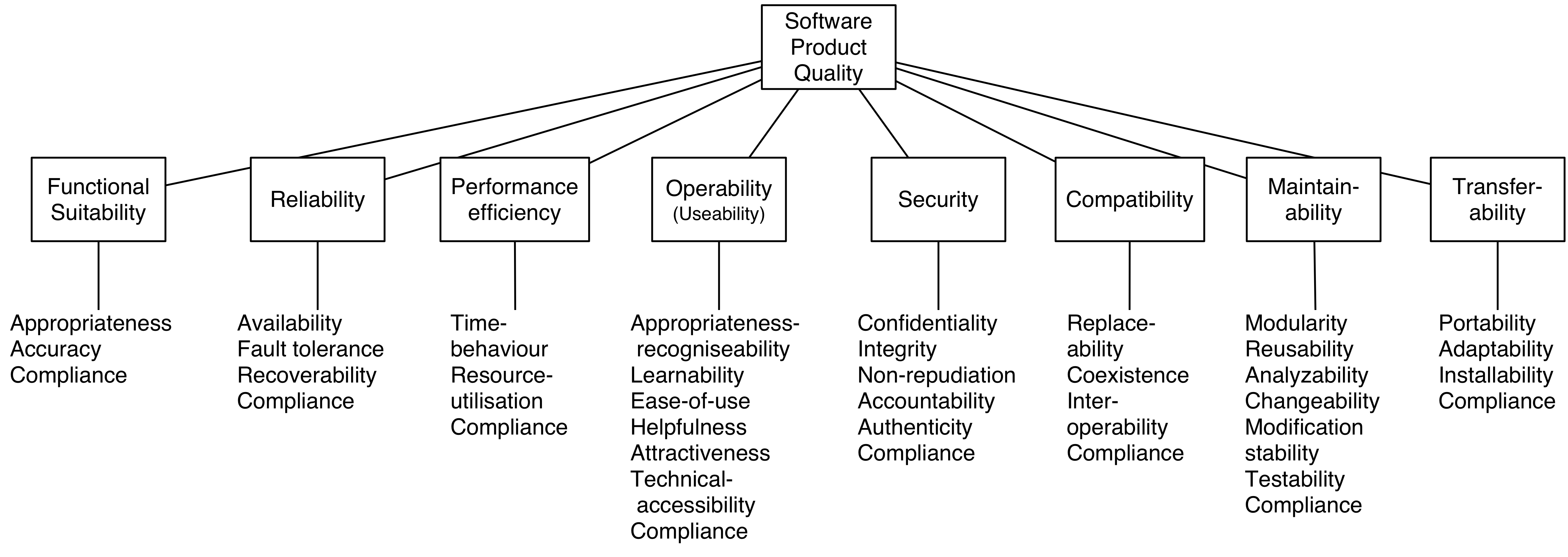
The ISO documents are not open. But since quality matters and ISO 25010 is used heavily for managing quality aspects within business IT systems you should keep these factors in mind when developing test to minimize business risks.
Data testing for ML pipelines is different and can be complex. Data preparation and testing for machine learning is not comparable with data testing for traditional IT projects. This is because it requires a statistical test performed on the data set. If input data changes this can have a significant effect on the outcome. Good statistical practice is an essential component of good scientific practice but also for real world ML applications. Especially when safety aspects play a role. Also mind that ML can be in essence is still seen as applied statistics. Validation of outcomes using statistical methods is proven science.
Good statistical practice is an essential component of good scientific practice but also for real world ML applications. Especially when safety aspects play a role. Also mind that ML can be in essence is still seen as applied statistics.
In statistical hypothesis testing, the p-value or probability value is the probability of obtaining test results at least as extreme as the results actually observed during the test. The p-value was never intended to be a substitute for scientific reasoning. Well-reasoned statistical arguments contain much more than the value of a single number and whether that number exceeds an arbitrary threshold. So for evaluating machine learning results the principles of American Statistical Association (ASA) can be useful. These principles are:
P-values can indicate how incompatible the data are with a specified statistical model.
P-values do not measure the probability that the studied hypothesis is true, or the probability that the data were produced by random chance alone.
Scientific conclusions and business or policy decisions should not be based only on whether a p-value passes a specific threshold.
Proper inference requires full reporting and transparency.
A p-value, or statistical significance, does not measure the size of an effect or the importance of a result.
By itself, a p-value does not provide a good measure of evidence regarding a model or hypothesis.
Machine learning projects tend to be pretty under-tested, which is unfortunate because they have all of the same complexity and maintainability issues as software projects.
Tests codify your expectations at the point when you actually remember what you’re expecting.
They allow you to offload verification to a machine.
You can make changes to your code with confidence.
Interoperability#
Open standards do help. And with open standards you should look for real open standards. There are standards that not only specify how things should work, but also have an open source implementation that is using the standards for real. Keep away from standards that exist on paper only or standards that only have a reference implementation. Good standards are used and born from a practical need.
In this way everyone implementing the standards is forced to make sure the outcome and use of APIs is the same. Most of the time open standards lack an open implementation, so vendors can implement the specification and still lock you in.
With interoperability for machine learning a trained model can be reused using different frameworks for an application. A trained model is the result of applying a machine learning algorithm to a set of training data. A new model using an already trained model can make predictions based on new input data. For example, a model that’s been trained on a region’s historical house prices may be able to predict a house’s price when given the number of bedrooms and bathrooms.
Currently de facto standards on machine learning are just emerging. But due to all tools offered for applying machine learning it makes sense that models can be reused between machine learning frameworks. Open Neural Network Exchange (ONNX) is the first step toward an open ecosystem that empowers AI developers to choose the right tools as their project evolves. ONNX provides an open source format for AI models. It defines an extensible computation graph model, as well as definitions of built-in operators and standard data types. Caffe2, PyTorch, Microsoft Cognitive Toolkit, Apache MXNet and other tools are developing ONNX support. Enabling interoperability between different frameworks and streamlining the path from research to production will increase the speed of innovation for ML applications. See: http://onnx.ai/ for more information.
A standard that is already for many years (first version in 1998) available is the PMML standard. This Predictive Model Markup Language (PMML) is an XML-based predictive model interchange format. However many disadvantages exist that seem to prevent PMML from becoming a real interoperability standard for ML. (See http://dmg.org/pmml/v4-3/GeneralStructure.html )
Besides standards on interoperability for use of machine learning frameworks you need some standardization on datasets first. The good news is that raw datasets are often presented in a standard format like csv, json or xml. In this way some reuse of data is already possible. But knowing the data pipeline needed for machine learning more is needed. E.g. Currently there is no standard way to identify how a dataset was created, and what characteristics, motivations, and potential skews it represents. Some answers that a good standardized metadata description on data should provide are e.g.:
Why was the dataset created?
What (other) tasks could the dataset be used for?
Has the dataset been used for any tasks already?
Who funded the creation of the dataset?
Are relationships between instances made explicit in the data?
What preprocessing/cleaning was done?
Was the “raw” data saved in addition to the preprocessed/cleaned data?
Under what license can the data be (re)used?
Are there privacy or security concerns related to the content of the data?
Debugging#
Machine learning is a fundamentally hard debugging problem. Debugging for machine learning is needed when:
your algorithm doesn’t work or
your algorithm doesn’t work well enough.
What is unique about machine learning is that it is ‘exponentially’ harder to figure out what is wrong when things don’t work as expected. Compounding this debugging difficulty, there is often a delay in debugging cycles between implementing a fix or upgrade and seeing the result. Very rarely does an algorithm work the first time and so this ends up being where the majority of time is spent in building algorithms.
Continuous improvements#
Machine learning models degrade in accuracy in production. This since the new input data is different from the used training data. Input data changes over time.This problem of the changes in the data and relationships within data sets is called concept drift.
Machine learning models are not a typical category of software. In fact a machine learning model should not be regarded as software at all. This means that maintenance should be organized and handled in a different way. There is never a final version of a machine learning model. So when using machine learning you need engineers that continuously updated and improved the model.
So setting up end user feedback, accuracy measurements, monitoring data trends are important factors for organizations when using machine learning. But the traditional IT maintenance task as monitoring servers, network and infrastructure, security threats and application health is also still needed.
Maturity of ML technology#
Machine Learning is moving from the realm of universities and hard core data science into a technology that can be integrated for mainstream application for every business. However machine learning technology is not yet idiot proof. Many algorithms are not used for real world applications on a large scale. Also many machine learning building blocks are still in heavy development. Of course in near future machine learning applications will never be idiot proof, since this is the nature of current machine learning technologies. But acceptable margins for normal errors and disasters are not yet solid predictable at the start of a project.
But thanks to the development of many quality OSS machine learning building blocks and platforms doing a Proof of Concept becomes within reach for every business.
FOSS Machine learning still needs a lot of boring work that is invisible but crucial for overall quality. The boring work is avoided at most universities and most companies choice the easy path towards commercial offerings. But for high value FOSS machine learning applications everyone who shares the principles for FOSS ML can and should contribute to the foundation work needed for machine learning.
Data and bias#
Machine learning is only as good as the data used for training. So too often machine learning applications are biased based. This is is a consequence of the used input.
In general almost all development time is spent on data related tasks. E.g. prepare data to be used as training data and manual classification.
Data is selecting is expensive and complex since often privacy aspects are involved.
“Garbage-in, garbage-out” is too often true for machine learning applications. The “black box” algorithms of machine learning prevents understanding why a certain output is seen. Often input data was not appropriate, but determining the root cause of the problem data is a challenge.
Bias is a problem that relates to output seen and has a root cause in the used input data set. Biased data sets are not representative, have skewed distribution, or contain other quality issues. Biased training data input results in biased output that makes machine learning application useless.
Dealing with unwanted bias in data is a challenging pitfall to avoid when using recommendations of algorithms. Bias challenges are playing out in health care, in hiring, credit scoring, insurance, and criminal justice.
When evaluating outcomes of machine learning applications there are many ways you can be fooled. Common data quality aspects to be aware of are:
Cherry picking: Only results that fit the claim are included.
Survivorship bias: Drawing conclusions from an incomplete set of data, because that data has survived the selection criteria.
False causality: Falsely assuming when two events appear related that one must have caused the other.
Sampling bias: drawing conclusions from a set of data that isn’t representative of the population you are trying to understand.
Hawthorne effect: The act of monitoring someone affects their behaviour, leading to spurious findings. Also known as the observer effect.
MCNamara fallacy: Relying solely on metrics in complex situations and losing sight of the bigger picture.
Machine learning can be easily susceptible to attacks and notoriously difficult to control. Some people are collecting public information regarding machine learning disasters and unethical applications in practice. A few examples:
AI-based Gaydar - Artificial intelligence can accurately guess whether people are gay or straight based on photos of their faces, according to new research that suggests machines can have significantly better “gaydar” than humans.
Infer Genetic Disease From Your Face - DeepGestalt can accurately identify some rare genetic disorders using a photograph of a patient’s face. This could lead to payers and employers potentially analyzing facial images and discriminating against individuals who have pre-existing conditions or developing medical complications. [Nature Paper]
Racist Chat Bots - Microsoft chatbot called Tay spent a day learning from Twitter and began spouting anti semitic messages.
Social Media Propaganda - The Military is studying and using data-driven social media propaganda to manipulate news feeds in order to change the perceptions of military actions.
Infer Criminality From Your Face - A program that judges if you’re a criminal from your facial features.
For the complete list and more examples, see: daviddao/awful-ai
Data quality and problems to get your data quality right before starting should be your greatest concern when starting with machine learning with a goal to develop a real production application.
Quality of Machine Learning frameworks#
Only a few people understand the complex mathematical algorithms behind machine learning. History learns that implementing an algorithms into software correctly has proven to be very complex and difficult. When you use FOSS machine learning software you have one large advantage over commercial ‘black-box’ software: You can inspect the software or ask an IT consultancy company to provide a quality audit.
The recent years there is a continuous growth of open machine learning tools and frameworks.Determining which toolkits are good enough for your business case is not trivial.
A simple checklist to start with this challenge:
A clear description of the used mathematical model and algorithm used must be available.
All source code, including all dependencies, including external libraries must be available for download and specified.
A test suite so you can analyse the machine learning framework (time, sample size) of the algorithm should be available.
A healthy open community should be active around the framework and eco-system. A healthy FOSS community has a written way of working, so it is transparent how governance of the software is arranged.
Openness: It should be transparent why people and companies contribute to the FOSS machines learning software.